



随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战。下面分享下对实际10万+峰值的平台的数据库优化方案
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战。下面分享下对实际10万+峰值的平台的数据库优化方案。与大家一起讨论,互相学习提高!
案例:游戏平台.
1、解决高并发
当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论。当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通过异步插入的方式改善了许多,但与此同时,对读取数据的实时性也需要做一定的牺牲。
异步的方式有很多,目前采取的方式是通过作业每隔一段时间(5min、10min..看需求设定)将临时表的数据转到真实表。
1. 已有原始表A 也是在读取的时候真正用到的表。
2. 建立与原始表A同结构的B和C,用来作数据的中转处理,同步流程是C->B->A。
3. 建立同步数据的作业Job1和记录Job1运行状态的表,在同步的时候比较关键的是需要检查Job1的当前状态,如果当前正在将B的数据同步到A,则把服务端过来的数据存到C,然后再把数据导入到B,等到下一次Job执行的时候再将这批数据转到A。如图1:
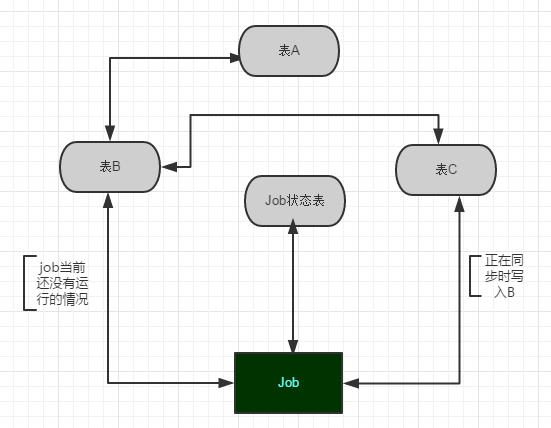
图1
同时,为保万无一失和便于排查问题,应该用一个记录整个数据库实例的存储过程,在较短的时间检查作业执行结果,如果遇到异常失败的,应该及时通过其他方式通知到相关人员。如写入到发邮件和短信表,让一个Tcp的通知程序定时读取发送等等。
注:如果一天的数据达到几十个G,如果又对这个表有查询要求(分区下面会提到),下策之一:
可将B同时同步到多台服务器分担下查询压力,减少资源的竞争。因为整个数据库的资源是有限的,如插入操作,会先获得一个共享锁,然后通过聚集索引定位到某一行数据,再升级为意向锁,而sqlserver对锁的维护根据数据的大小需要申请不同的内存,造成了资源的竞争。所以应该尽可能的将读和写分开,可根据业务模型分,可根据设定的规则分;在平台性的项目中应该优先保证数据能有效的插入。
在不可避免的查询大数据肯定会耗用大量的资源,如遇到批量删除的时候,可以换成以循环分批次(如一次2000条)的方式,这样不至于这个进程导致整个库挂掉,衍生出一些无法预计的bug。经实践,有效可行,只是牺牲了存储空间。也可根据查询需求将表里数据量大的字段拆分出来到新表,当然这些也要根据每个业务场景结合需求来设定,设计出适合而并不需要华丽的方案即可。
2、解决存储问题
如果每天单表的数据都达到了几十个G,改善存储方案自然迫不及待了。现分享下自有的方案,在暴涨的数据摧残之下,仍坚守在一线!现举例对自有环境分享拙见:
现有数据表A,单表每天新增数据30G,在存储的时候采用异步将数据同步的方式,有的不能清除数据的表,在分区后还可分文件组,将文件组分配到不同的磁盘中,减少IO资源的竞争,保障现有资源的正常运行。现结合需求保留历史数据5天:
1. 这时需要通过作业job根据分区函数去生成分区方案,如根据userid或者时间字段来分区;
2. 将表分区后,查询可以通过对应的索引,快速定位到某一段分区;
3. 通过作业合并分区将不要的分区数据转移到相同结构和索引的表,然后清除这个表的数据。
如图2:

图2
通过sql查询跟踪捕捉到查询耗时长的,以及通过sql自带的存储过程sp_lock或视图dm_tran_locks、dblockinfo查看当前实例存在的锁的类型和粒度。
定位到具体的查询语句或者存储过程之后,对症下药!药到病除!
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持脚本之家!
声明:本文内容来源自网络,文字、图片等素材版权属于原作者,平台转载素材出于传递更多信息,文章内容仅供参考与学习,切勿作为商业目的使用。如果侵害了您的合法权益,请您及时与我们联系,我们会在第一时间进行处理!我们尊重版权,也致力于保护版权,站搜网感谢您的分享!

