



出品|虎嗅科技组作者|齐健编辑|陈伊凡头图|电影《华尔街之狼》3月2日,OpenAI正式开放了ChatGPT的API接口,开发人员可以将ChatGPT模型集成到他们的应用程序和产品中。ChatGPTAPI调用的价格以Token(数字代币)计算,0.002美元可以获得1000Token,1000个Token约等750个单词

出品|虎嗅科技组
作者|齐健
编辑|陈伊凡
头图|电影《华尔街之狼》
3月2日,OpenAI正式开放了ChatGPT的API接口,开发人员可以将ChatGPT模型集成到他们的应用程序和产品中。ChatGPT API调用的价格以Token(数字代币)计算,0.002美元可以获得1000 Token,1000个Token约等750个单词。这个价格比ChatGPT刚刚开放测试时大幅下降,OpenAI官方称,12月以来,OpenAI为ChatGPT降低了90%的成本。
与ChatGPT一同开放API的还有OpenAI的语音转文字模型Whisper,如果开发人员把这两个模型结合起来应用到自己的App中,没准也能造出一个钢铁侠的“贾维斯”。
与科技行业大环境的停滞与衰退不同,AI产业正在逆流而上,关于ChatGPT和通用AI大模型的讨论一浪接着一浪,现在几乎每周都会有几条关于生成式AI以及AI大模型的热点新闻。
在加密货币频频暴雷后,风险投资领域太需要一个刺激神经的技术了。
2月28日,百度官宣了将在3月16日召开发布会,公开自己的类ChatGPT产品“文心一言”。在此之前,Meta也宣布将开源一个用于科研的大模型系列LLaMA。
在微软高调把ChatGPT推到New Bing的台前后,硅谷巨头们就开始紧锣密鼓地推动大模型研究,谷歌仅用两个月就发布了类似ChatGPT的Bard。
在这方面,中国并不落后。2023年2月起,百度、阿里、腾讯、京东、字节等纷纷发声表示自己在大模型领域已经开展了深入研究,且获得了很多成果。一时间,追逐大模型成了国内AI行业的标准动作,“大练模型到炼大模型”的过度期似乎已经接近尾声,下一阶段大有“全民大模型,ChatGPT进万家”的架势。
不过,AI技术研发不是谁都能做的,需要真正的专家。硅谷巨头之所以能在大模型领域迅速反应,一方面因为他们在这条赛道上有多年的技术积累,更重要的是他们在AI研究方面有着大量的人才储备。
谷歌的人工智能研究团队一直处在全球领先地位,旗下还有与OpenAI齐名的实验室DeepMind;另一家科技巨头Meta则有被称为卷积神经网络之父的图灵奖得主Yann LeCun以首席AI科学家的身份坐镇。
微软手下的急先锋OpenAI,也是基于强大的科研团队才奠定的领先地位。科技情报分析机构AMiner和智谱研究发布的《ChatGPT团队背景研究报告》显示,OpenAI的ChatGPT研发团队中,27人为本科学历,25人为硕士学历,28人为博士研学历(注:5人信息缺失),占比分别为33%、30%、37%。
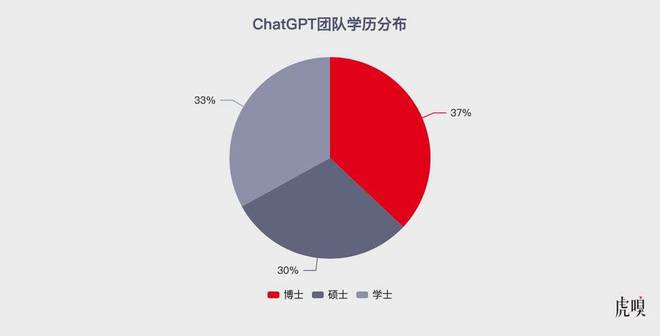
ChatGPT团队学历分布
而另一份来自猎聘大数据的国内AI人才市场调查则显示:近一年,预训练模型、对话机器人和AIGC三个ChatGPT相关领域中,国内企业明确要求本科以上学历的职位分别占71.33%、82.30%、92.53%;要求硕、博士学历的占比分别为16.49%、9.86%、18.22%。
对比ChatGPT团队,国内AI人才的平均水平差距较大,硕博比例明显不足。而在今天这种大家齐上大模型赛道的“加速”发展态势下,要在短时间里“大干快上”,势必要先比试比试谁的团队技术实力强,谁更能在自己的麾下聚拢一批大模型人才。
抢人大作战
技术大战开打之前,各家的大模型团队先得打赢一场关键的人才争夺战。
如果你是一个清华博士,有5-10年NLP(Natural Language Processing,自然语言处理)行业经验,那么你的资料只要出现在招聘平台上,不需要任何详细履历,就可以在注册完成后的48小时内,接到多家猎头公司的询问电话,以及数十条HR、猎头、业务经历甚至BOSS本人发来的站内信息。在这些信息中,不乏阿里、美团、小红书等大厂,还有诸多创业公司,以及研究机构。猎头们提供的NLP算法研究员岗位年薪也大多会在百万元上下。
根据猎聘大数据调查,过去五年,人工智能和互联网的招聘薪资均处于上涨态势,人工智能年均招聘薪资明显高出互联网。2022年,人工智能招聘平均年薪为33.15万元,比互联网高出4.27万元,即14.78%。
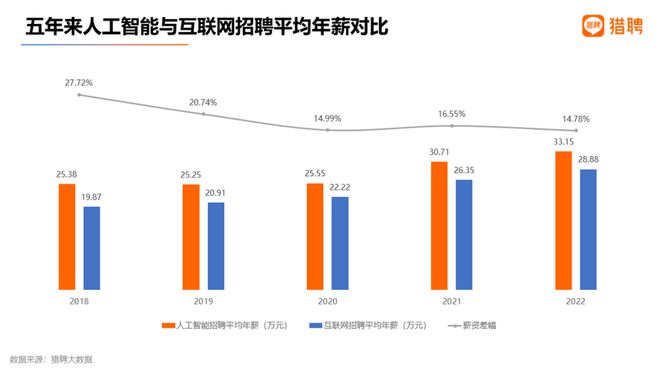
五年来人工智能与互联网招聘平均年薪对比
在ChatGPT爆火后,这样的情况越来越明显。据上述调查显示,与ChatGPT相关的岗位工资均超过平均水平,AIGC为39.08万,对话机器人为34.89万,预训练模型为33.93万。“ChatGPT一火起来,AI工程师的薪资水平也越来越高,你不开高价就抢不到人。”某AI领域投资人对虎嗅说。
从技术的角度看,大模型发端于NLP领域,自然语言处理岗位在人工智能领域一直都处于人才稀缺的状态,薪酬水平处于高位。科锐国际调研咨询业务负责人&高科技领域资深专家景晓平对虎嗅表示,“人工智能行业典型岗位按产业链划分,技术层和基础层薪酬水平处于高位,高于互联网其他领域薪酬水平,应用层和互联网常规岗位薪酬一致。”
事实上,近年来国内AI人才的硕博占比也在逐年提升,很多企业对AI领域的人才要求学历至少是硕士。薪酬结构则与企业的性质密切相关,国有企业、研究所的薪酬主要是固定薪酬、项目奖金和津贴,例如,国内第一梯队的AI实验室,清华大学计算机系自然语言处理与社会人文计算实验室(THUNLP)挂在官网上的博士后招聘待遇为年薪30万,享受清华大学教职工社会保险、住房公积金等待遇。提供公寓或每年4.2万的租房补贴,同时可以解决子女入园、入学。
IT大厂和AI创业公司的薪酬结构则多为,固定薪资+浮动奖金+股权期权激励。在猎聘、脉脉、BOSS直聘三个平台搜索ChatGPT,硕博学历职位的月薪普遍高于3万,最高达9万。“在薪酬方面IT大厂并不会占多少便宜,AI大模型的研发都是高举高打,创业公司给出的薪酬可能更有竞争力。”西湖心辰COO俞佳认为,没有资金支持很难在大模型的基础训练领域推动一家初创公司,对于这个领域来说,钱的问题可能“不是最大的问题”。
猎聘、脉脉、BOSS直聘,搜索ChatGPT的前排结果
此外,在诸多岗位信息中,工作地点集中在北京、上海、杭州和深圳,但其中一些职位也并不限制办公地。景晓平表示,目前国内AI人才北京占据第一位,上海、广东省分列二三位,近些年互联网发展极为活跃的浙江省,在人工智能发展上也丝毫不落风头,成都作为科技新秀城市,有优质相关生源的地域,也储备了不少人工智能人才。但从需求总量来看,国内AI人才还有很大缺口。
OpenAI的专家团队为何强
OpenAI官网挂出的参与过ChatGPT的项目团队共87人,该团队平均年龄为32岁,其中90后是主力军。
《ChatGPT团队背景研究报告》显示,ChatGPT研发团队绝大多数成员拥有名校学历,成员最集中的前5大高校是:斯坦福大学(14人)、加州大学伯克利分校(10人)、麻省理工学院(7人)、剑桥大学(5人)、哈佛大学(4人)和佐治亚理工学院(4人)。
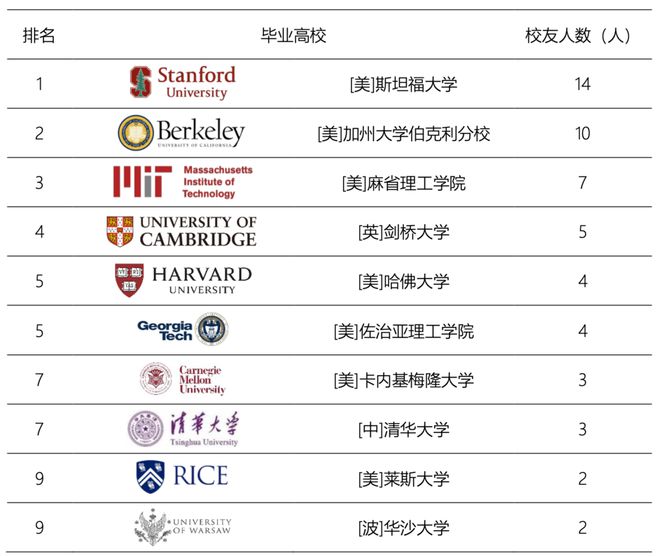
ChatGPT 团队成员毕业前10名高校
此外,很多成员都有名企工作经历,包括:Facebook、Stripe、Uber、Quora、NVIDIA、Microsoft、Dropbox、DeepMind、Apple、Intel等公司,其中有10人来自谷歌,OpenAI的首席科学家Ilya Sutskever亦是从谷歌转会而来,Ilya Sutskever是AlphaGo的作者之一,师从人工智能学界泰斗Geoffrey Hinton。
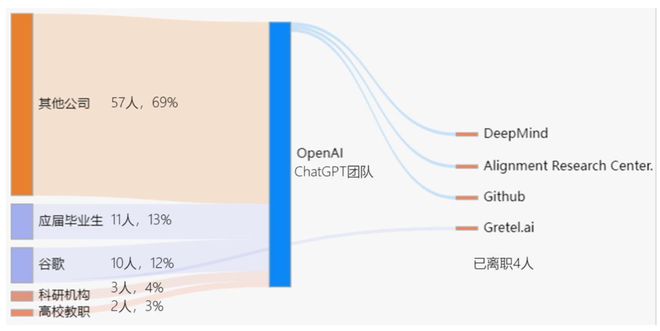
ChatGPT团队成员流动示意图
1985年出生在苏联的Ilya Sutskever,如今已经是英国皇家学会院士。据说Ilya Sutskever退出谷歌,与Sam Altman、Elon Musk等人一起创立OpenAI时,年薪曾大幅缩水。但他参与创立OpenAI的初衷是“确保强大的人工智能造福全人类”的大义和情怀。
OpenAI初创之时是一家非营利研究机构,从这点上来看,无论是否带着情怀加入这家公司的研究人员,还是给“非营利”事业烧钱的投资人,多少都有一点对技术的“信仰”,这种驱动力,可能是钱买不来的。
不过OpenAI给这些科技精英们提供的薪酬待遇并不低。据纽约时报报道,2016年,OpenAI向Ilya Sutskever支付了超过190万美元。另一位行业大佬级的研究员Ian Goodfellow(对抗式生成网络的提出者)2016年从OpenAI得到的报酬则超过80万美元,而他在这一年中只工作了9个月,不过Ian Goodfellow在OpenAI没有待很长时间就离开了。
一直以来,硅谷的AI研究员都是高收入人群。在谷歌发布的官方招聘信息中,在美国工作的全职“高级软件工程师,大型语言模型,应用机器学习”(Staff Software Engineer, Large Language Models, Applied ML)岗位基本工资范围为年薪17.4万-27.6万美元(约120万-190万元人民币)+奖金+股权+福利。
这份工作的主要职责是:为谷歌大型语言模型的关键冲刺做出贡献,将尖端的LLM(Large Language Mode,大型语言模型) 引入下一代谷歌产品和应用程序,以及外部用户。在建模技术方面进行协作,以支持全方位的LLM调整,从提示工程、指令调整、基于人类反馈的强化学习(RLHF)、参数高效调整到微调。
微软研究院的研究员岗位“博士后研究员-机器学习和强化学习”(Post Doc Researcher-Machine Learning and Reinforcement Learning)年薪则在9.4万-18.2万美元(约64万-125万元人民币)。工作职责是“与其他研究人员合作制定自己的研究议程,推动有效的基础、基础和应用研究计划。”
ChatGPT团队中另一个有意思的点是团队中有9位华人成员,其中5人本科毕业于国内高校,美国学界对人才的虹吸效应也正是硅谷巨头以及“OpenAI”们强大人才竞争力的基础。
“中国的AI人才是从14亿人里挑,美国是从80亿人里挑,全世界优秀的人很多都到美国去了。”图灵联合创始人、原智源研究院副院长刘江表示,要承认差距确实存在,不过他也表示,“在这方面,我们也不用气馁。中国也有自己的优势,比如市场化、产品化的能力,近年来我们不比美国同行差了。”
国内大厂的实力如何?
除了人才问题,国内大模型研究落后美国另一个原因是在生成式AI和大模型研究方面起步略晚,而起步晚的原因,则还是与“钱”脱不开关系。
从技术角度看,生成式技术在Stable Diffusion和ChatGPT等网红产品出现之前,技术实现的效果并不理想,且需要消耗大量算力进行研究。所以大厂、资本很难斥以重资,投入到这种看上去不太赚钱,还要烧钱的业务。
中国的AI产业更注重应用场景,而非基础理论和技术创新。各家大厂在NLP的理解方面有很多成熟业务,比如听写、翻译,在视觉识别和AI大数据处理方面也有很多应用场景。所以这部分业务自然是AI研发的主力,一方面他们赚钱,另一方面在这些领域的技术积累,使研究人员能够“在规定跑道上赛跑”,而不是在未知领域探路。
这一点不只是限制了国内公司,更是很多全球巨头的创新桎梏。正如诺基亚做不出iPhone一样,巨头都不喜欢“破坏式创新”,谷歌发布的Bard只因一个小失误就牵动了母公司Alphabet的万亿市值,这也正是谷歌一直声称不愿发布LaMDA大模型的理由,害怕会因AI的失误影响自己的商誉。而OpenAI显然不太在乎ChatGPT在公测中会出什么问题,毕竟他发布ChatGPT时只是一家估值200亿美元的独角兽。
不过,在这波大模型的追赶赛中,国内大厂的团队也可以说是实力颇强。
百度在大模型方面走的最早,百度自2019年开始研发预训练模型,先后发布了知识增强文心(ERNIE)系列模型。文心大模型研发的带头人,百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰博士,是自然语言处理领域权威国际学术组织ACL(Association for Computational Linguistics)的首位华人主席、ACL亚太分会创始主席、ACL Fellow,还是IEEE Fellow、CAAI Fellow及国际欧亚科学院院士。他还兼任中国电子学会、中国中文信息学会、中国工程师联合体副理事长等。目前,王海峰在国内外期刊会议上发表的学术论文有200余篇,获得已授权专利170余项。
虽然没有像百度一样公布类ChatGPT产品的发布时间表,但腾讯、阿里和华为分别提出的“混元”、“通义”和“盘古”三个大模型,均已研发了很长时间。
据机器学习和自然语言处理著名学者Marek Rei教授在2022年4月发布的统计(2023年的统计尚未发布)显示,2012-2021年中,在ML(Machine Learning,机器学习)和NLP顶级期刊和会议发表论文数量最多的机构是谷歌,微软紧随其后。发文数量最多的中国机构是清华大学,第二是位列第16的腾讯,腾讯也是前32名中唯一的中国互联网厂商。不过,在2021年单年的统计中,阿里和华为也登上此榜,腾讯仍排在较靠前的位置。
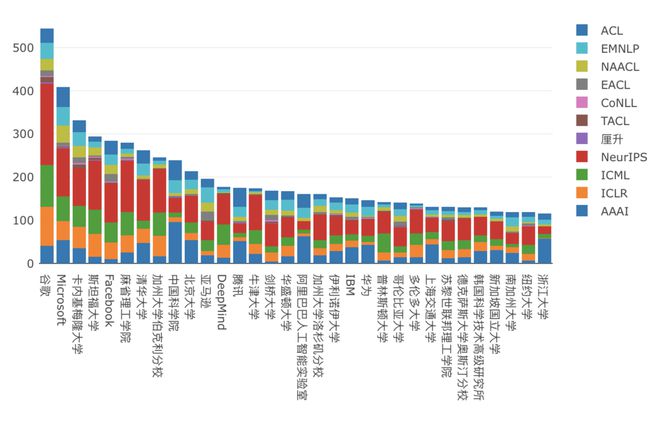
Marek Rei发布的2021年ML、NLP顶会、期刊发文量统计
目前,腾讯官方并没有公布“混元”大模型研发团队的具体信息。不过,腾讯旗下AI研发团队“腾讯AI Lab”的专家构成,也显示出了腾讯在AI领域的一部分实力。腾讯AI Lab由100余位AI科学家和超过300名应用工程师组成,带头人张正友博士是腾讯首席科学家、腾讯 AI Lab 及 Robotics X 实验室主任,腾讯首位17级研究员、杰出科学家。他在美国斯坦福大学(Stanford University)发布的2022 年度“全球前2%顶尖科学家榜单”(World's Top 2% Scientists 2022)中,排名全球“终身科学影响力排行榜”第1002名,中国排名 Top 10。
阿里在LLM领域的研究主要由阿里巴巴达摩院负责,阿里巴巴集团资深副总裁,阿里云智能CTO、达摩院副院长周靖人主导,他是IEEE Fellow,多次担任VLDB,SIGMOD,ICDE等国际顶级会议程序委员会主编、主席,在顶尖国际期刊和会议上发表论文超百篇,并拥有几十项技术专利。
华为也未对“类ChatGPT产品”公开表态,但在大模型方面华为亦有“盘古”大模型正在研究。该项目由华为云人工智能领域首席科学家田奇博士领导,他是计算机视觉、多媒体信息检索专家,IEEE Fellow,国际欧亚科学院院士,教育部长江讲座教授,国家自然科学基金海外杰青,中国科学院海外评审专家,在国内多所高校任讲席教授及客座教授。
在自己组建团队投入研发的同时,百度、阿里、腾讯、华为等IT大厂,也与中科院计算所自然语言处理研究组、哈尔滨工业大学自然语言处理研究所、中国人民大学高瓴人工智能学院等高校研究有很多的技术合作。
“集中力量办大事”的科研机构
数据闭环是大模型研发的关键,用户越多,积累时间越长,就意味着可以用于迭代升级的数据和反馈也就越多。
在这方面OpenAI已经利用前两代的开源GPT模型和GPT-3积累了大量数据。ChatGPT虽然才推出了3个月,但用户量和访问量增长速度飞快,这些都为OpenAI在大模型研发方面积累了巨大的先发优势。
“AI大模型如果落后了,就会面临卡脖子的风险。”很多AI专家对此都有担心,由此国内也诞生了一些应对此种局面的非营利性AI科研机构。这些机构多数有高校研究实验室背景加持,以及地方政策支持,人才聚拢能力非常强劲。
北京智源人工智能研究院(以下简称“智源研究院”)是科技部和北京市政府共同支持,联合北京人工智能领域优势单位共建的非营利性创新性研发机构。智源研究院理事长张宏江,是美国国家工程院外籍院士,ACM Fellow和IEEE Fellow,同时也是微软亚洲研究院的创始人之一。
2021年,智源研究院发布了1.7万亿参数的超大模型“悟道”的1.0和2.0版本,这项工作由100余位科学家共同打造。其中包括清华大学计算机系自然语言处理与社会人文计算实验室(THUNLP)的孙茂松教授,清华大学知识工程研究室(KEG)的唐杰教授,清华大学交互式人工智能课题组(CoAI)的黄民烈教授。
目前“悟道”大模型已经与OPPO、好未来、淘宝、搜狗、美团等开展了落地合作。在与美团的合作中,大模型给搜索广告带来了2.7%的收入增长。
在南方的科技重镇也有一家相似的研究机构,粤港澳大湾区数字经济研究院(以下简称IDEA研究院),IDEA研究院是由深圳市政府大力支持的AI研究机构。与智源研究院有一个颇有趣的相似之处,IDEA研究院的创始人沈向洋博士同样出身微软亚洲研究院。沈向洋博士是美国国家工程院外籍院士和英国皇家工程院外籍院士,他参与创建了微软亚洲研究院,担任院长兼首席科学家,并曾担任微软公司全球执行副总裁,主管微软全球研究院和人工智能产品线,并负责推动公司中长期总体技术战略及前瞻性研究与开发工作。
IDEA研究院NLP研究中心负责人张家兴博士也来自微软亚洲研究院,他的团队推出的开源模型“太乙”,据称在中文文生图领域可以达到接近Stable Diffusion(一款开源文生图AI模型)的水平。
目前IDEA研究院正在持续迭代开发的预训练模型体系“封神榜”,已经开源了6个系列共10个模型,包含4种模型结构,模型参数最大为35亿。其中包括:以Encoder结构为主的双向语言系列模型的二郎神系列;面向医疗领域,拥有35亿参数的余元系列;与追一科技联合开发的新结构大模型周文王系列;以Decoder结构为主的单向语言模型闻仲系列;以Transformer结构为主的编解码语言模型,主要解决通用任务的大模型燃灯系列;以及主要面向各种纠错任务的比干系列。
2月20日晚,复旦大学自然语言处理实验室对媒体宣传邱锡鹏教授团队发布了“国内第一个对话式大型语言模型MOSS”,并在公开平台(https://moss.fastnlp.top/),邀请公众参与内测。然而就在外界都等着看MOSS表现如何惊艳之时。MOSS的内测网站却挂出了一则道歉公告。
目前MOSS的测试网站已经挂出了停止服务的公告。一位AI大模型专家对虎嗅表示,“邱锡鹏的实验室学术研究的氛围很浓。虽然这次的MOSS很少有人得到体验机会,但是从后边的公告来看,有可能是在工程优化,并发处理等方面的准备还没有那么充分。”
在近期举行的2023年世界人工智能开发者先锋大会上,邱锡鹏教授公开表示,如果优化顺利,MOSS计划在2023年3月底开源。
虽然,没能成功抢发“国产ChatGPT”,但AI业内人士对邱锡鹏教授团队仍然给出了肯定的评价,“邱锡鹏教授的团队比较偏重学术,这和早期的OpenAI在科研心态上是有共性的,非营利性的AI研究机构,没有那么多功利的考虑。”
创业公司都有“大佬”背书
AI技术属于计算机科学,虽然计算机技术已发展多年,但AI仍属于前沿科技,对LLM以及其他通用大模型的研究更是兴起不久,仍然需要依靠应用数据,持续迭代升级,不管MOSS是不是因为工程经验绊了跟头,要在AI、大模型这些领域实现突破,能推广到市场中,接地气的技术和产品才是王道。事实上,目前国内AI行业活跃的实验室大多已开始尝试商业化,在市场的磨砺中探索大模型未来的出路。
深言科技
深言科技源自清华大学计算机系自然语言处理与社会人文计算实验室(THUNLP)。THUNLP由清华大学人工智能研究院常务副院长孙茂松,以及刘洋、刘知远,三位教授带头。实验室在2017年推出的中文诗歌自动生成系统「九歌」则是最有影响的诗歌生成系统之一,「九歌」已经为用户创作了超过3000万首诗词。
孙茂松教授领衔研发的CPM模型是智源研究院的大模型「悟道·文源」的前身,也是国内最成熟的中文生成式大模型之一。深言科技的团队也是由CPM模型的部分研发团队成员所组成的,目前该公司产品包括可以根据意思搜索词语的“WantWords反向词典”,以及根据意思查询句子的“WantQuotes据意查句”。
智谱AI
智谱AI的前身是清华大学知识工程研究室(KEG),KEG专注研究网络环境下的知识工程,在知识图谱、图神经网络和认知智能领域已发表一系列国际领先的研究成果。2006年,智谱AI就启动了科技信息分析引擎ArnetMiner(以下简称AMiner)的相关研究,先后获得了国际顶级会议SIGKDD的十年最佳论文(Test-of-Time Award)、国家科学进步奖二等奖、北京市发明专利奖一等奖。
2022年8月,由KEG与智谱AI共同研发的千亿级模型参数的大规模中英文预训练语言模型GLM-130B正式发布,其在多个公开评测榜单上超过GPT-3 v1。此外,智谱AI还打造了认知大模型平台(BigModel.ai),形成AIGC产品矩阵,提供智能API服务。
聆心智能
2月17日,聆心智能宣布完成由无限基金SEE Fund领投的Pre-A轮融资。聆心智能的底层技术是超拟人大规模语言模型,基于大模型可控、可配置、可信的核心技术优势,聆心智能推出“AI乌托邦”,该系统允许用户快速定制 AI 角色。
聆心智能由清华大学交互式人工智能课题组(CoAI)黄民烈教授支持。CoAI是清华大学朱小燕教授及黄民烈教授领导的实验室。2020年,就已经开源了1200万对话数据和中文对话预训练模型CDial-GPT。黄民烈教授也曾参与了智源研究院的“悟道”大模型研发。
西湖心辰
西湖心辰背靠西湖大学深度学习实验室,创始人是西湖大学助理教授、博士生导师蓝振忠,主要研究大规模预训练模型的训练与应用。蓝振忠曾在谷歌担任研究科学家,也是轻量化大模型ALBERT的第一作者。
西湖大学在人工智能领域的研发实力很强,除了蓝振忠博士的深度学习实验室,西湖大学NLP实验室,在该领域的研究也非常领先。学术带头人张岳博士在Marek Rei教授的顶会、期刊发文量统计中,于2012-2021年期间排名全球第四。
“目前国内LLM领域的创业公司相对IT大厂来说主要有两个优势,技术和数据。”西湖心辰COO俞佳对虎嗅表示,国内大模型创业公司在技术方面普遍已有多年研究经验,构筑了一定的技术壁垒,这是很难短期超越的。同时,由于已经推出了相关产品,“数据飞轮”已经转起来了,这些数据的质量相比互联网数据质量要高很多,能够对产品迭代起到很大支撑作用。
对于国内大模型创业公司未来的发展趋势,俞佳认为可能性很多,“有些公司可能会走出自己的道路,也有的公司可能会像OpenAI一样与IT大厂开展深度合作,甚至像DeepMind直接并入其中。”
声明:本文内容来源自网络,文字、图片等素材版权属于原作者,平台转载素材出于传递更多信息,文章内容仅供参考与学习,切勿作为商业目的使用。如果侵害了您的合法权益,请您及时与我们联系,我们会在第一时间进行处理!我们尊重版权,也致力于保护版权,站搜网感谢您的分享!

